百度开源分布式深度学习平台:Paddle
百度分布式深度学习平台Paddle宣布开源,支持Python、C++和SWIG,支持多机数据并行的深度学习模型训练,并提供了Sequence to Sequence模型的Demo。
Paddle团队在Github上介绍,PaddlePaddle(PArallel Distributed Deep LEarning,并行分布深度学习)是一个易于使用、高效灵活、可扩展的深度学习平台,最初由百度科学家和工程师团队为将深度学习算法应用到很多百度产品上而开发。
特性
PaddlePaddle的四个特性简介如下:
- 灵活性:PaddlePaddle支持广泛的神经网络结构和优化算法,很容易配置复杂的模型,如基于注意力(Attention)机制或复杂的内存(Memory)连接的神经机器翻译模型。(Attention和Memory参考阅读: 深度学习和自然语言处理中的attention和memory机制 深度学习:推动NLP领域发展的新引擎 )
- 高效:在PaddlePaddle的不同层面进行优化,以发挥异构计算资源的效率,包括计算、内存、架构和通信等。例如:
- 通过SSE/AVX内部函数,BLAS库(例如MKL,ATLAS,CUBLAS)或定制CPU/GPU内核优化的数学运算。
- 高度优化循环网络,以处理可变长度序列,无需填充(Padding)。
- 优化高维稀疏数据模型的本地和分布式训练。
- 可扩展性:PaddlePaddle很容易使用多个CPU/GPU和机器来加快你的训练,通过优化通信实现高吞吐量、高性能。
- 连接产品:PaddlePaddle易于部署。在百度,PaddlePaddle已经被部署到广大用户使用的产品或服务,包括广告点击率(CTR)的预测,大型图像分类,光学字符识别(OCR),搜索排名,计算机病毒检测,推荐等。
PaddlePaddle支持使用Python接口或C++来构建系统,可以使用SWIG为开发者喜爱的编程语言创建接口。
Github上目前提供了图像分类、情绪分析、Sequence to Sequence模型、推荐和语义角色标注(SRL)等五个Demo。
使用
Quick Start Tutorial看这里。涵盖深度学习应用的五个环节。

Logistic Regression、Word Embedding、CNN、RNN等不同网络架构如下:
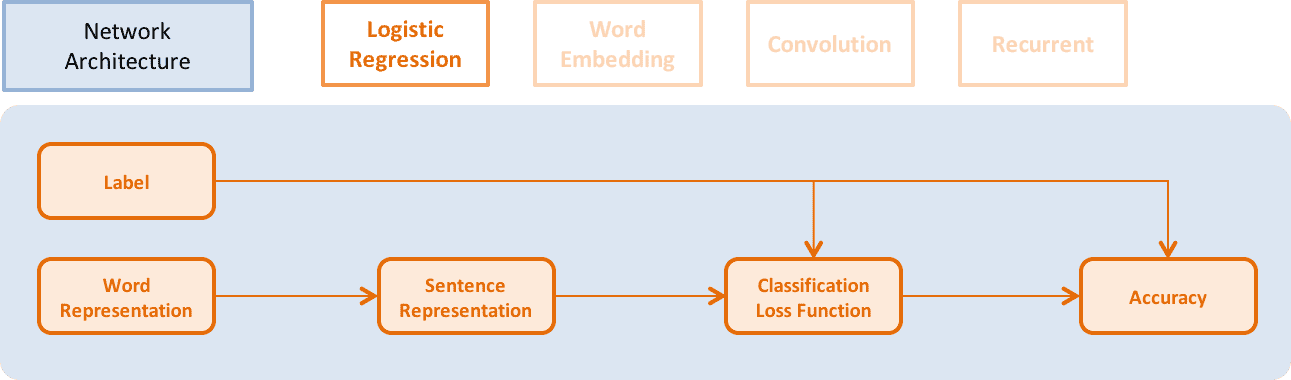
↑↑↑ Logistic Regression
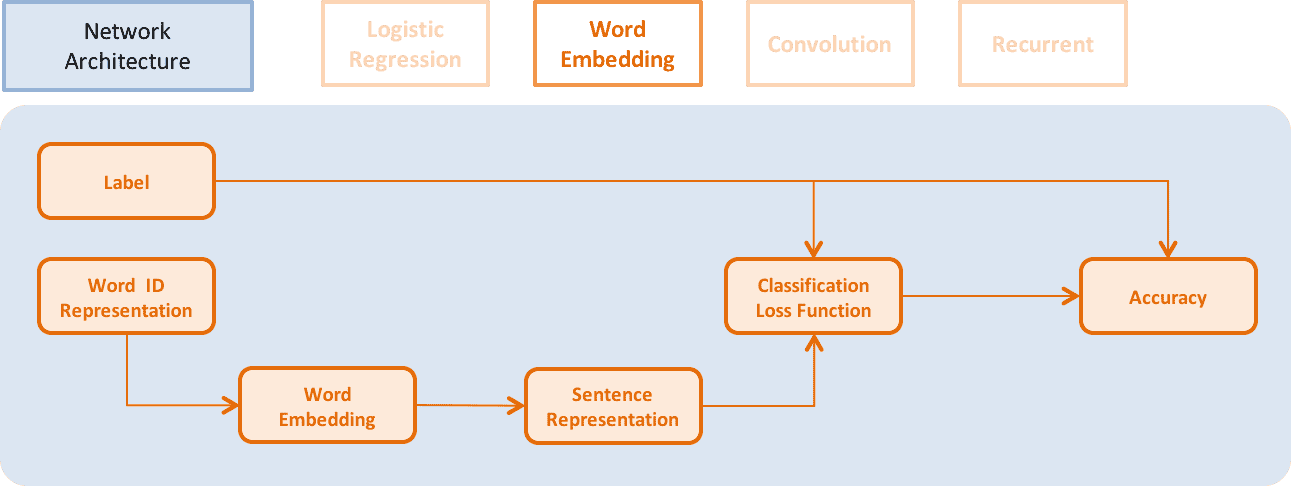
↑↑↑ Word Embedding Model
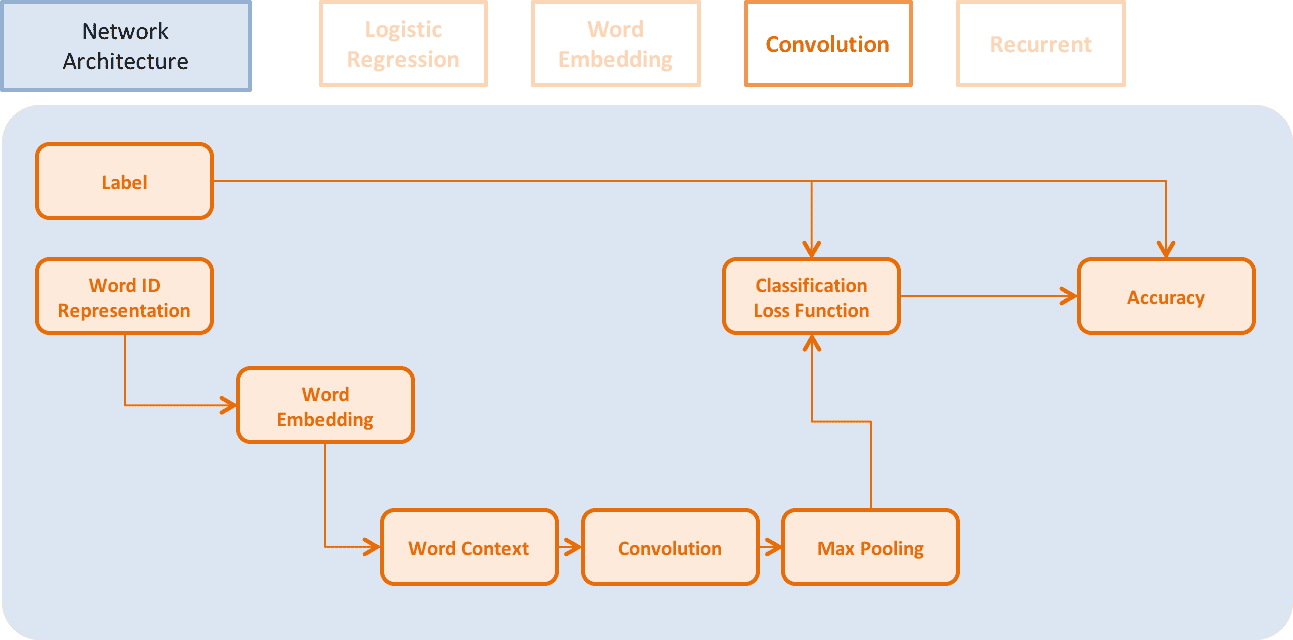
↑↑↑ Convolutional Neural Network Model
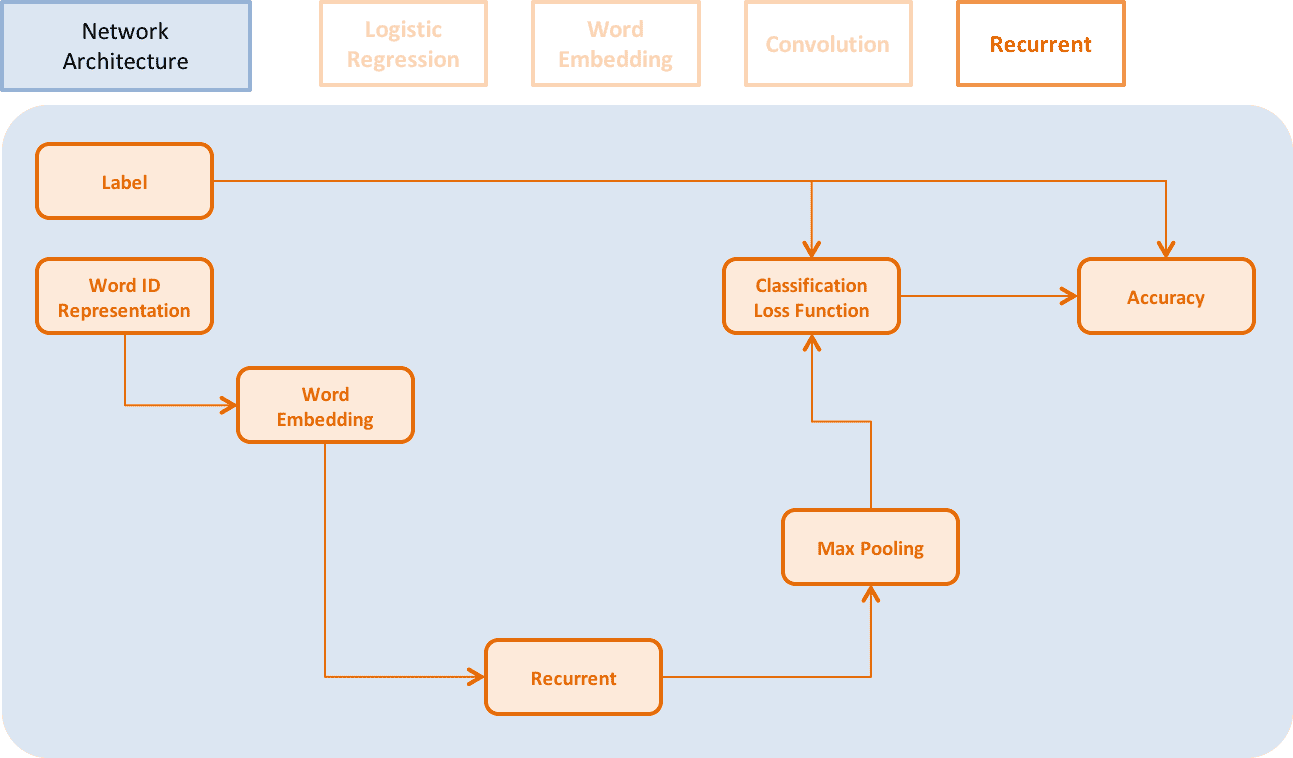
↑↑↑ Recurrent Model
算法优化包括 Momentum, RMSProp, AdaDelta, AdaGrad, Adam 和 Adamax。这里可以使用极为适合循环神经网络的Adam优化方法及L2正则化和gradient clipping。
settings(batch_size=128,
learning_rate=2e-3,
learning_method=AdamOptimizer(),
regularization=L2Regularization(8e-4),
gradient_clipping_threshold=25)源码文档在这里。方法和模型的讨论,可以联系paddle-dev@baidu.com。
深度学习, 人工智能
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
