深度 | DeepMind官方深度解读:使用合成梯度的解耦神经接口(附论文)
DeepMind 开发的许多算法都使用到了神经网络。例如,AlphaGo 使用卷积神经网络对围棋棋盘进行评估。同时在电子游戏中,DQN 与深度强化学习算法使用神经网络来选择操作,从而在视频游戏上实现了超人级的水平。8 月 20 号,机器之心发布的文章《 学界 | 谷歌DeepMind最新论文:使用合成梯度的解耦神经接口 》介绍了他们在此方面的新研究。今日,DeepMind 发表官方博客对此研究进行了详细解读。文中提到的论文可点击「阅读原文」下载。_
这篇文章介绍了我们最近一些关于神经网络能力的进步与相应的训练过程的研究,我们称其为使用合成梯度的解耦神经接口(Decoupled Neural Interfaces using Synthetic Gradients)。这项工作给了我们一种在神经网络之间实现通信的方式,从而让它们可以学习彼此发送消息;这种方法是通过一种去耦合、可扩展的方式在多个神经网络之间实现通信,或者提升循环神经网络的长期时间依赖性( long term temporal dependency )。这是通过使用一个逼近误差梯度(error gradients)的模型实现的,而没有特别使用反向传播来计算误差梯度。这篇文章的剩余部分假设读者对神经网络与如何训练神经网络已有一定的了解。如果你是刚刚接触这部分领域的新手,我们推荐 YouTube上的《Nando de Freitas lecture series》系列了解深度学习与神经网络。
神经网络与锁的问题
考虑神经网络中的任意一层或一个模块,当其之后网络中的模块已经执行并且梯度已经回传给它,那它只能被更新一次。例如这样一个简单的前馈网络:

在 Layer 1 处理完输入后,它只能在输出激活(output activations,黑线)被传播通过神经网络的剩余部分、然后产生一个损失(loss)并反向传播误差梯度(绿线)直到达到 Layer 1 之后才能被更新。这一系列的操作意味着 Layer 1 在其能更新之前必须等待 Layer 2 与 Layer 3 的前向传播与反向传播的计算。对于神经网络剩余部分,Layer 1是被锁住的、是耦合的。
为什么这是个问题?显然对于如前描绘的前馈网络而言,我们并不需要担心这个问题。但考虑一下带有多个网络的、以异步和不规则的时间尺度在多种环境中工作的复杂系统。

或者一台分布于多台机器的大型分布式网络。有时候需要网络中的所有模块需要等待网络中的其它所有模块都执行完成和反向传播梯度,这个过程非常耗时,而且甚至无法解决。如果我们解耦了这些模块之间的接口——连接,那么我们就能让每一个模块都独立地更新,而不会受到网络中其它的部分的锁定。
所以,我们如何解耦神经接口(即解耦网络模块之间的连接),并同时仍然能保证这些模块能够继续从交互中学习呢?在这篇论文中,我们移除了对获取误差梯度(error gradient)的反向传播的依赖,并转而学习了一个可以预测哪些梯度将仅基于局部信息的参数模型。我们将预测出来的梯度称为合成梯度(synthetic gradients)。

该合成梯度模型可以从模块中获取激活(activation),并产生将会成为误差梯度(error gradient)的预测——误差梯度是指在特定激活下网络的损失的梯度。
回到我们简单的前馈网络的例子,如果我们有一个合成梯度模型,我们可以执行下图的操作
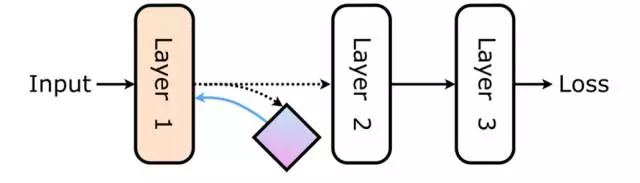
并甚至能在网络中其它部分得到执行之前就使用该合成梯度(蓝色)更新 Layer 1.
该合成梯度模型本身的训练是为了回归( regress)目标梯度——这些目标梯度可能是从损失(loss)或其它合成梯度反向传播回来的真实梯度;而那些其它合成梯度又是从更下游的合成梯度模型中反向传播得到的。

这种机制普遍出现在任意两个模块之间的通信,而不只是在前馈网络中。这种机制的具体工作流程如下图,其中一个模块的颜色变化代表该模块的权重的更新。

因此在一个神经网络中使用解耦神经接口(DNI)去掉了之后的模块对先前的模块的锁定。在论文的实验部分,在 CIFAR-10 图像分类问题上,我们使用合成梯度,并且每层均为去耦合的这种方式训练网络,可以和使用反向传播方式进行训练达到同样的准确度。 要认识到 DNI 不是如魔法般地允许不使用真实的梯度信息训练网络。真实的梯度信息确实会通过网络向后渗入,但是相比于通过合成梯度模型的损失值,其速度较为缓慢,并且需要大量的训练迭代次数。合成梯度模型近似以及平滑真实梯度的消失。
在这点上有一个适当的问题需要考虑,这些合成梯度模型增加了多少计算复杂度——大概你需要一个与网络本身复杂度相同的合成梯度模型架构。令人惊喜的是,合成梯度模型能够非常简单。对于前馈网络,我们的确可以发现,即使单线性层(single linear layer )也能作为合成梯度模型良好地工作。因此,这是非常容易训练的,并且能够迅速产生合成梯度。
DNI 能适用任一通用的神经网络架构,而不只是前馈网络。一个有趣的项目就是循环神经网络(RNN)。一个 RNN 有一个展开的、反复使用的循环核心(recurrent core)来处理序列数据。训练 RNN 的理想情况是:我们能在整个序列(可能无限长)上展开该核心,使用沿时间的反向传播(BPTT)将误差梯度传播穿过整个图(graph)。

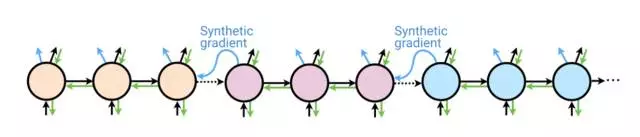
然而在实践中,由于内存的约束以及需要频繁计算更新我们的核心模型,我们只能在有限的步上展开。这被称之为截断的沿时间的反向传播(truncated BPTT),下图给出了截断成 3 个步骤的示意:
![]

核颜色的改变代表着核的更新,即权重得到更新。在这个例子中,截断 BPTT 看起来解决了训练的一些问题——我们现在能够每三个步骤更新一次我们核的权重,并且只需要内存中的三个核心(core)。然而事实上,并不存在超过三个步骤的误差梯度的反向传播,这意味着核的更新并不会受到未来超过 2 个步骤的误差的直接影响。这限制了 RNN 可以学习用来建模的时间依赖。
如果我们不在 BPTT 的边界之间使用反向传播,而是使用 DNI 和产生合成梯度,那么未来的误差梯度将会成为哪种模型?我们可以将一个合成梯度模型整合到核心中,以使得在每一个时间步骤,该 RNN 核都会在产生输出的同时产生合成梯度。在这个案例中,该合成梯度是在考虑了之前时间步骤的隐状态激活后所预测出的所有未来损失的梯度。这个合成梯度只能用在截断 BPTT( truncated BPTT )的边界(我们之前在这里无法得到梯度)。
这可以在训练过程中非常高效地执行——它几乎不需要我们像图中那样在内存中保留额外一个核。其中绿色虚线边框表示的只是关于输入状态的梯度的计算,而绿色实线边框则是额外考虑了核参数的梯度计算。
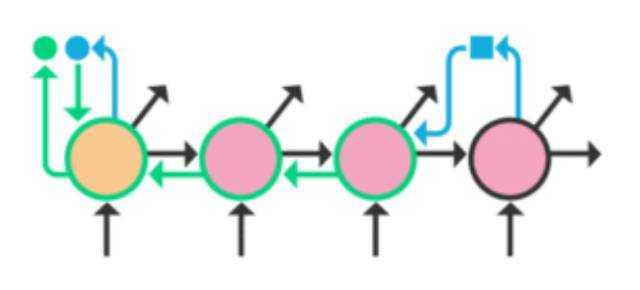
通过与 RNN 一起使用 DNI 和合成梯度,我们近乎是在一个无限展开的 RNN 中进行反向传播。事实上,这可以得到能建模更长的时间依赖( longer temporal dependencies)的 RNN。下面是来自这篇论文的一个结果例子:
训练过程中的 Penn Treebank 测试误差(更低更好)
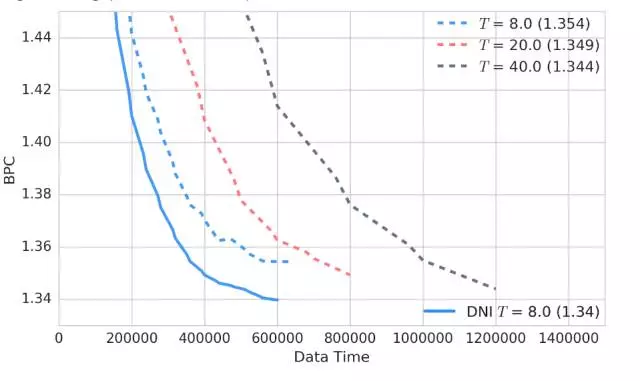
Penn Treebank 是一个语言建模问题;这幅图给出了在 Penn Treebank 上的下一个字符预测(next character prediction)上训练的一个 RNN 应用。y 轴表示每字符位数(BPC: bits-per-character),其数字是越小越好。x 轴表示训练过程中该模型所看到的字符的数量。蓝色、红色和灰色的虚线是使用截断 BPTT 训练的 RNN,分别展开了 8 步、20 步和 40 步——RNN 在执行沿时间的反向传播(BPTT)前被展开的步数越多,模型就越好,但训练就越慢。当将 DNI 用在展开了 8 步的 RNN 上时(蓝色实线),该 RNN 能够实现 40 步模型那样的长期依赖(long term dependency),但训练速度却达到了它的两倍(在常规的带有单个 GPU 的桌面机器上,但数据时间和实际时间上都更快)。
重申一下,我们增加的合成梯度模型让我们可以解耦在网络的两个部分之间的更新。DNI 还可以应用在分层 RNN 模型(以不同时间尺度运行的两个或更多个 RNN)上。正如我们在论文中给出的那样,DNI 能通过实现更高水平模块的更新率来显著提升这些模型的训练速度。
希望本文的解释能让你了解我们在这篇新论文中所报告的实验:显然创造解耦神经接口是可能的。这是通过创建能够获取局部信息和预测误差梯度的合成梯度模型实现的。在较高的层面上,这可被认为是一种两个模块之间的通信协议。一个模块发送信息(当前激活),另一个接收这个信息并使用一个效用模型(model of utility ,即该合成梯度模型)来对其进行评估。该效用模型允许接收方向发送方提供实时反馈(合成梯度),而不再需要等待该信息的真实效用的评估(通过反向传播)。这个框架也可以在误差批评(error critic)的角度进行思考(论文:HANDBOOK OF INTELLIGENT CONTROL),这有些类似于在强化学习中使用批评(论文:Direct Gradient-Based Reinforcement Learning:II. Gradient Ascent Algorithms and Experiments)。
这些解耦神经接口允许网络的分布式训练、能增强用 RNN 学习到的时间依赖、还能加速分层 RNN 系统。我们很兴奋地将继续探索 DNI 的未来,因为我们认为这将成为一个重要的基础,让我们可以开拓更模块化的、解耦的和异步的模型框架。最后,相关的更多细节、技巧和全部实验请查阅论文《Decoupled Neural Interfaces using Synthetic Gradients》。
- 论文:使用合成梯度的解耦神经接口(Decoupled Neural Interfaces using Synthetic Gradients)

摘要:训练 directed neural networks 通常需要将数据前向传播通过一个计算图(computation graph),然后再反向传播误差信号,从而生成权重更新。因此,网络中所有层——或称为模块(modules)——就会被锁定,在某种意义上,它们必须等待该网络的剩余部分前向执行,然后反向传播误差之后才能实现更新。在本研究成果中,我们通过引入网络图(network graph)的一个未来计算模型而对模块进行解耦,从而打破了这种限制。这些模型仅使用局部信息就能预测建模的子图(subgraph)将会产生的结果。我们尤其关注建模误差梯度(modelling error gradients):通过使用建模的合成梯度来取代真正的反向传播误差梯度,我们可以解耦子图并独立和异步地对它们进行更新,即我们可以实现解耦神经接口。我们展示了三项实验结果,前向传播模型(其中每一层都是异步训练)、循环神经网络(RNN)(预测某个未来梯度可在 RNN 可以有效建模的时间上进行扩展)、和一个分层 RNN 系统(在不同时间尺度上)。最后,我们证明:除了预测梯度,该框架还可被用于预测输入,得到可以以前向和反向通过的方式解耦的模型——从而发展成可以联合学习(co-learn)的独立网络,它们可通过这种方式被组合成一个单一的 functioning corporation。
投资文献, 神经网络, 梯度
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!
